


把一些前后端概念性比较强的理念放在这里,本篇设计CI、CD、RPC、PWA等
https://segmentfault.com/a/1190000038774393?utm_source=sf-related
CDN
CDN,即Content Delivery Network,内容分发网络,其搭建的思路是尽可能避开网上有可能影响数据传输速度和稳定性的瓶颈和环节,尽量使内容传输的更快更稳定。
CDN通过在网络边缘部署边缘服务器,依靠CDN中心平台的负载均衡、内容分发以及调度等功能,使用户就近获取所需的内容,降低网络延迟,提高用户响应速度和命中率。所以CDN就是广泛采用各种缓存服务器,使得用户的请求直接由这些缓存服务器响应,加快了响应速度。只有在用户请求的资源在缓存服务器上没有找到或者请求访问的资源在源站点服务器上已经修改过的情况下,缓存服务器才会去访问源站点服务器以获取最新的资源
在CDN环境下,web访问数据通常会经历客户端本地缓存和CDN边缘节点缓存两个阶段。如果这两个阶段均无法响应客户端请求,那么最后会由CDN节点向源站点发出回源请求,进而从源站点获取最新的数据,更新CDN节点的本地缓存,最后将新的数据返回给客户端。
CDN节点的缓存机制也是遵循http协议,也会收到cache-control等字段的影响, 与此同时,CDN的缓存时间的长短对回源率产生直接影响。若CDN缓存时间较短,CDN边缘节点的数据经常失效,导致频繁回源,增加了源站的负载,同时也增大访问延时,若CDN缓存时间太长,会带来数据更新时间慢的问题。因此开发者需要针对特定的业务,做特定的时间缓存管理
回源/回源比
回源是指浏览器在发送请求报文时,响应请求报文的是源站点的服务器,而不是各节点上的缓存服务器,这个过程称为回源
回源的请求或者流量太多,有可能会让源站点的服务器承载着过大的访问压力,进而影响服务的正常访问
回源请求数比例:回源请求数/(回源请求数+用户发送的请求数)
回源流量比:回源流量/(回源流量+用户请求访问的流量)
函数式编程与面向对象编程
OOP的中心原则是数据和对它的操作紧密结合:对象拥有它的数据,并且它拥有对数据的实现。它通过接口、响应方法和消息的集合来隐藏对象,因此抽象中心是数据本身,以接口的形式隐藏在API后面
OOP的中心活动是组成新对象并通过向现有对象添加新方法来拓展现有对象
fp的中心原则是数据只是松散地耦合到函数上。您可以在同一个数据结构上编写不同的操作,抽象的中心模型是函数,而不是数据结构。函数隐藏了它们的实现,语言的抽象以及它们组合或表达的方式
fp的中心活动是编写新函数
PWA
PWA(progressing web app),渐进式网页应用程序,是Google在2016年GoogleI/O大会上提出的下一代web应用模型,并在随后的日子里迅速发展。 一个 PWA 应用首先是一个网页, 可以通过 Web 技术编写出一个网页应用. 随后借助于 App Manifest 和 Service Worker 来实现 PWA 的安装和离线等功能。
PWA的特点:
渐进式:适用于选用任何浏览器的所有用户,因为它是以渐进式增强作为核心宗旨来开发的。
自适应:适合任何机型:桌面设备、移动设备、平板电脑或任何未来设备。
连接无关性:能够借助于服务工作线程在离线或低质量网络状况下工作。
离线推送:使用推送消息通知,能够让我们的应用像 Native App 一样,提升用户体验。
及时更新:在服务工作线程更新进程的作用下时刻保持最新状态。
安全性:通过 HTTPS 提供,以防止窥探和确保内容不被篡改。
基于这些特点,对于移动端h5页面和app,增加了可以添加至屏幕的功能,点击主屏幕图标可以实现启动动画以及隐藏地址栏实现离线缓存功能,即使用户手机没有网络,依然可以使用一些离线功能。 这些特点和功能不正是我们目前针对移动web的优化方向吗,有了这些特性将使得 Web 应用渐进式接近原生 App,真正实现秒开优化。
Service Worker 是一个 基于HTML5 API ,也是PWA技术栈中最重要的特性, 它在 Web Worker 的基础上加上了持久离线缓存和网络代理能力,结合Cache API面向提供了JavaScript来操作浏览器缓存的能力,这使得Service Worker和PWA密不可分。
Service Worker的特点
一个独立的执行线程,单独的作用域范围,单独的运行环境,有自己独立的context上下文。
一旦被 install,就永远存在,除非被手动 unregister。即使Chrome(浏览器)关闭也会在后台运行。利用这个特性可以实现离线消息推送功能。
处于安全性考虑,必须在 HTTPS 环境下才能工作。当然在本地调试时,使用localhost则不受HTTPS限制。
提供拦截浏览器请求的接口,可以控制打开的作用域范围下所有的页面请求。需要注意的是一旦请求被Service Worker接管,意味着任何请求都由你来控制,一定要做好容错机制,保证页面的正常运行。
由于是独立线程,Service Worker不能直接操作页面 DOM。但可以通过事件机制来处理。例如使用postMessage。
Service Worker的生命周期
注册(register):在浏览器解析到JavaScript需要先注册Service Worker时的逻辑,即调用navigator.serviceWorker.register()时所处理的事情。
安装中( installing ):发生在 Service Worker 注册之后,表示开始安装。
安装后( installed/waiting ):Service Worker 已经完成了安装,这时会触发install事件,在这里一般会做一些静态资源的离线缓存。如果还有旧的Service Worker正在运行,会进入waiting状态,如果你关闭当前浏览器,或者调用self.skipWaiting(),方法表示强制当前处在 waiting 状态的 Service Worker 进入 activate 状态。
激活中( activating ):表示正在进入activate状态,调用self.clients.claim())会来强制控制未受控制的客户端,例如你的浏览器开了多个含有Service Worker的窗口,会在不切的情况下,替换旧的 Service Worker 脚本不再控制着这些页面,之后会被停止。此时会触发activate事件。
激活后( activated ):Service Worker激活成功,在activate事件回调中,一般会清除上一个版本的静态资源缓存,或者其他更新缓存的策略。这代表Service Worker已经可以处理功能性的事件fetch (请求)、sync (后台同步)、push (推送),message(操作dom)。
废弃状态 ( redundant ):Service Worker 的生命周期结束。
利用web
Web Push是一个基于客户端,服务端和推送服务器三者组成的一种流程规范,可以分为三个步骤:
- 客户端完成请求订阅一个用户的逻辑。
- 服务端调用遵从 web push 协议的接口,传送消息推送(push message)到推送服务器(该服务器由浏览器决定,开发者所能做的只有控制发送的数据)。
- 推送服务器将该消息推送至对应的浏览器,用户收到该推送。
实例(js)
1 | //在页面代码里面监听onload事件,使用sw的配置文件注册一个service worker |
service worker的局限
Service Worker必须是https协议的,但本地环境下http://localhost或者http://127.0.0.1也可以的。
浏览器兼容性:部分浏览器不支持
serviceworker缓存与http缓存
http缓存是涉及到cache-control, Etag, last-modified 等字段,断网的时候,都不能访问,缓存不能编程,不能精细地对需要缓存的内容增删改查,
serviceworker缓存:基于 Web Worker ,一个独立的 worker 线程,独立于当前网页进程;让缓存做到优雅和极致
Service Worker为PWA赋能离线可用性以及push消息:
和 CacheStorage 搭配,可以做离线应用
和 Notification 搭配,可以做像 Native APP 那样的消息推送
再加上 Manifest 等,就差不多成了 PWA 了
webworker与service worker
webworker是现代浏览器提供的一个js多线程方案,可以将一些大计算量的代码交给web worker运行。js语言执行的是单线程语言,也就是说所有任务排成一个队列,而有了webworker就不一样
兼容性:
手机浏览器不支持,ie10、火狐3.6、safari4.0、chrome和opera11
支持api:
结束worker:主页面worker.terminal() 或者worker自销毁self.close;或者关闭页面
service worker
service worker是基于webworker的事件驱动的,他们执行的机制都是新开一个线程去处理额外的、以前不能处理的任务
对于web worker,可以用来进行复杂的计算,因为它不阻塞浏览器主线程的渲染,而service worker可以用来进行本地缓存或者请求转发,相当于浏览器本地的proxy
总结
(1)webworker现在可以在浏览器端做多线程操作,但是比较限制
(2)serviceworker是在webworker基础上实现的,可以认为是使用webworker技术来处理网络请求、响应等问题
(3)两者的浏览器兼容性都不是很好,尤其是serviceworker,草案在更新,特性没有完整
(4)serviceworker可以带来更多
https://juejin.im/post/6844903896893095949#heading-5
https://juejin.im/post/6844904182839771143
serviceworker与其他缓存方案
目前webapp缓存方案:
1.基于头部信息的缓存方式。使用浏览器头部信息缓存主要有两种,一种是判断静态资源http头部的etag和last-modified是否修改,修改则重新请求,否则忽略;还有一种是根据expire过期时间定的,原理一样,但是两种方法都会产生大量http请求,即返回304,离线后就没有办法请求。
2.使用app cache。将要缓存的静态文件声明在一个manifest的文件清单里,然后在要缓存的html里通过manifest属性关联清单文件即可在下次载入html入优先加载缓存清单中的静态文件。
缺点:
manifest一次更新就全部更新
可以在打开app之前预缓存,提前下载文件或者更新manifest文件
还是有全部的304请求
3.localstorage存储。对于cookie确实丰富了很多,也扩大了容量,方便易用的api也被广泛接受,但是同样无法对静态文件进行存储,二是大小限制,虽然每个浏览器的localstorage大小不一样,但是最大也只有ie的7mb,对于离线应用显然是不够的
4.indexDB缓存:indexedDB的做法是把一些数据存储到浏览器的indexedDB中,当网络断开时,可以从浏览器中读取数据,用来做一些离线应用,而且不需要去写特定的sql语句,它是nosql 的,数据形式使用的是json。这种存储数据的方式似乎无懈可击,容量足够,存储自由,但是对于静态文件及极其麻烦。
serviceworker相对于上述的优点:
它可以是浏览器提供给用户的上网代理,通过fetch连接到用户的所有请求,可以不向服务器发送,并可以将请求转向本地缓存或者其他资源文件的加载,无论数据还是静态文件,可以通过js的操作进行增量更新,同事不阻塞渲染进程,这就很好地解决了问题
单点登录
单点登录简称为SSO,是目前比较流行的企业业务整合的解决方案之一。SSO的定义是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统。
SSO一般都需要一个独立的认证中心,子系统的登录均得通过passport,子系统本身将不参与登录操作,
CAS是中央认证服务的简称,是耶鲁大学发起的开源项目,旨在为Web应用系统提供一种可靠的单点登录方法。CAS包括两个部分:CAS server和CAS client,CAS server需要独立部署,主要负责对用户的认证工作,CAS Client负责处理对客户端受保护资源的访问请求,需要登录时重定向到CAS Server。
CAS与OAuth2的区别
1 CAS的单点登录时保障客户端的用户资源的安全,OAuth2则是保障服务端用户资源的安全
2 CAS的单点登录资源都在客户端这边,不在CAS的服务器那一方,用户在CAS服务端提供了用户名密码之后作为CAS客户端并不知道这件事,随便给客户端一个ST,那么客户端是不能确定这个ST是用户伪造还是真的有效,拿着这个ST去服务端再问一下,这个用户给我的是有效的ST还是无效的ST,OAuth2认证资源都在OAuth2服务提供者那一方,客户端
3 CAS登录和OAuth2在流程上的最大区别就是,通过ST或者code去认证时,需不需要预先商量好的密码
前端性能体验
延迟与用户反应
0-16ms 人们特别擅长跟踪运动,如果动画不流畅,他们就会对运动心生反感。用户可以感知每秒 60帧的平滑动画转场,也就是每帧16ms,留给应用大约10ms的时间来生成一帧
0-100ms 在此时间内窗口响应用户操作,用户会觉得立即获得结果,时间再长,操作与反应之间的 连接就会中断
100-300ms 用户会遇到轻微可觉察的延迟
300-1000ms 在此窗口内延迟感觉像任务自然和持续发展的一部分,对于网络上的大多数用户,加 载页面或者更改视图代表着一个任务
1000+ms 超过1s,用户的注意力将离开他们正在执行的任务
10000+ms 用户将感动失望,可能会放弃任务,之后或许他们不会再回来
埋点
埋点,是网站分析的一种常用的数据采集方法。我们主要用来采集用户行为数据(例如页面访问路径,点击了什么元素)进行数据分析,从而让运营同学更加合理的安排运营计划。
为了更精准地触达用户痛点,定位转化低点,提升业务赋能,基于数据分析的优化策略势在必行。
数据埋点分析系统的构成:
1.埋点采集JSSDK:收集用户行为数据,并进行上报
2.数据处理服务:接收上报数据并存储,筛取所需数据,进行数据处理并透出
3.数据可视化平台:汇总展示详细数据,支持自定义,打通业务
4.Chrome插件工具:在页面上直观展示坑位数据,提供场景更友好的可视化服务
基本的流程是:用户进入平台任意一个已埋点的Web页面,进行一系列地操作,都会由JSSDK进行分类并将数据上报至服务端进行存储,再由站点/插件发起查询,服务端将处理后的数据返回,再通过数据可视化平台进行透出展示。
数据采集一般分为三种:
1.无埋点(全埋点):零埋点成本,抓取用户行为全量数据,任何操作都会被上传,数据量大,噪音多。手动代码埋点比较常见,需要调用埋点的业务方在需要采集数据的地方调用埋点的方法。优点是流量可控,业务方可以根据需要在任意地点任意场景进行数据采集,采集信息也完全由业务方来控制。这样的有点也带来了一些弊端,需要业务方来写死方法,如果采集方案变了,业务方也需要重新修改代码,重新发布。
2.可视化埋点:在页面中操作,选择埋点位置/模块,非开发人员也能埋点。可是化埋点是近今年的埋点趋势,很多大厂自己的数据埋点部门也都开始做这块。优点是业务方工作量少,缺点则是技术上推广和实现起来有点难(业务方前端代码规范是个大前提)。阿里的活动页很多都是运营通过可视化的界面拖拽配置实现,这些活动控件元素都带有唯一标识。通过埋点配置后台,将元素与要采集事件关联起来,可以自动生成埋点代码嵌入到页面中。
3.侵入式埋点(手动埋点):埋点时需要将数据采集代码写入业务代码中,埋点成本高,准确度也更高。手动代码埋点比较常见,需要调用埋点的业务方在需要采集数据的地方调用埋点的方法。优点是流量可控,业务方可以根据需要在任意地点任意场景进行数据采集,采集信息也完全由业务方来控制。这样的有点也带来了一些弊端,需要业务方来写死方法,如果采集方案变了,业务方也需要重新修改代码,重新发布。
状态机
有限状态机,英文翻译是 Finite State Machine,缩写为 FSM,简称为状态机。状态机有 3 个组成部分:状态(State)、事件(Event)、动作(Action)。其中,事件也称为转移条件(Transition Condition)。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。
前端自动化测试
自动化测试的最大优势就是可以快速而且反复地进行测试。
前端自动化测试有个金字塔理论,把测试从上到下分为UI测试(用户界面测试)/Service(服务测试)/Unit(单元测试)
越往金字塔底层测试的效率越高,测试质量保障程度越高,测试的成本越低。也就是说,前端项目通常UI变化频繁,一旦发生变化,UI测试就无法执行且难以维护,所以UI自动化测试的成本高收益小,相比UI测试,Service测试更加简单直接且变化不会很频繁。单元测试主要对公共函数、方法进行测试,测试用例复用度高且更能保证代码质量。
我们开发项目时通常会选择使用框架和库,使用框架的好处是约束我们代码的风格,保证代码的可维护性和扩展性,使用工具库可以提高开发效率,同理,在实施自动化测试时我们也会选择使用测试框架和库,目前市面上比较流行的前端测试框架有Mocha、QUnit、Jasmine、Jest等。
Mocha:适用于Nodejs和浏览器、简易、灵活、有趣的JavaScript测试框架
Jest:由Facebook开源的JavaScript测试框架,应用于脸书系以及ReactJs系
Jasmine:BDD(行为驱动开发)测试框架,不依赖于browser、DOM以及js,适合website和nodejs项目
Qunit:一个易于使用的Javascript单元测试框架,由开发jQuery的团队开发,所以多用于jQuery相关的项目
以Mocha为例
Mocha的四项核心能力
测试用例分组、生命周期函数、兼容不同风格断言、同步异步测试框架
测试框架;Mocha
断言库:chai
测试覆盖率:Istanbul
测试浏览器:chrome
浏览器驱动:selenium-webdriver/chrome
接口测试http请求断言:supertest
react组件测试:enzyme
基准测试:benchmark
WebRTC
WebRTC(Web Real-Time Communication)是一种实时通讯技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器点对点的连接,实现视频流和音频流或其他任意数据的传输,WebRTC包含的这些标准使用户在无需安装任何插件或者第三方软件的情况下,创建点对点的数据分享和电话会议成为可能。
它并不是单一的协议,包含了媒体、加密、传输层等在内的多个协议标准,以及一套基于JavaScript的API,通过简单易用的JavaScript API,在不安装任何插件的情况下,使浏览器拥有P2P音视频和数据分享的能力。同时WebRTC并不是一个孤立的协议,它拥有灵活的指令,可以便捷地实现对接现有SIP和电话网络的系统。
WebRTC有三个模块:
Voice Engine(音频引擎):
Voice Engine 包含iSAC/iLBC Codec(音频编码解码器,前者是针对宽带和超宽带,后者是针对窄带)
NetEQ for voice(处理网络抖动和语音包丢失)
Echo Canceler(回声消除器)/Noise Reduction(噪声抑制)
Video Engine(视频引擎):
- VP8 Codec(视频图像编码解码器)
- Video jitter buffer(视频抖动缓冲器,处理视频抖动和视频信息包丢失)
- Image enhancements(图像质量增强)
Transport:
- SRTP(安全的实时传输协议,用音视频流传输)
- Multiplexing(多路复用)
- P2P,STUN+TURN+ICE(用于NAT网络和防火墙穿越的)
- 除此之外,安全传输可能还会用到DTLS(数据报安全传输),用于加密传输和密钥协商
- 整个WebRTC通信都是基于UDP的
WebRTC的核心组件:
音视频引擎:OPUS、VP8/VP9、H264
传输层协议:底层传输协议为UDP
媒体协议:SRTP/SRTCP
数据协议:DTLS/SCTP
P2P内网穿越:STUN/TURN/ICE/Trickle ICE
信令与SDP协商:HTTP/WebSocket/SIP、Offer Answer 模型
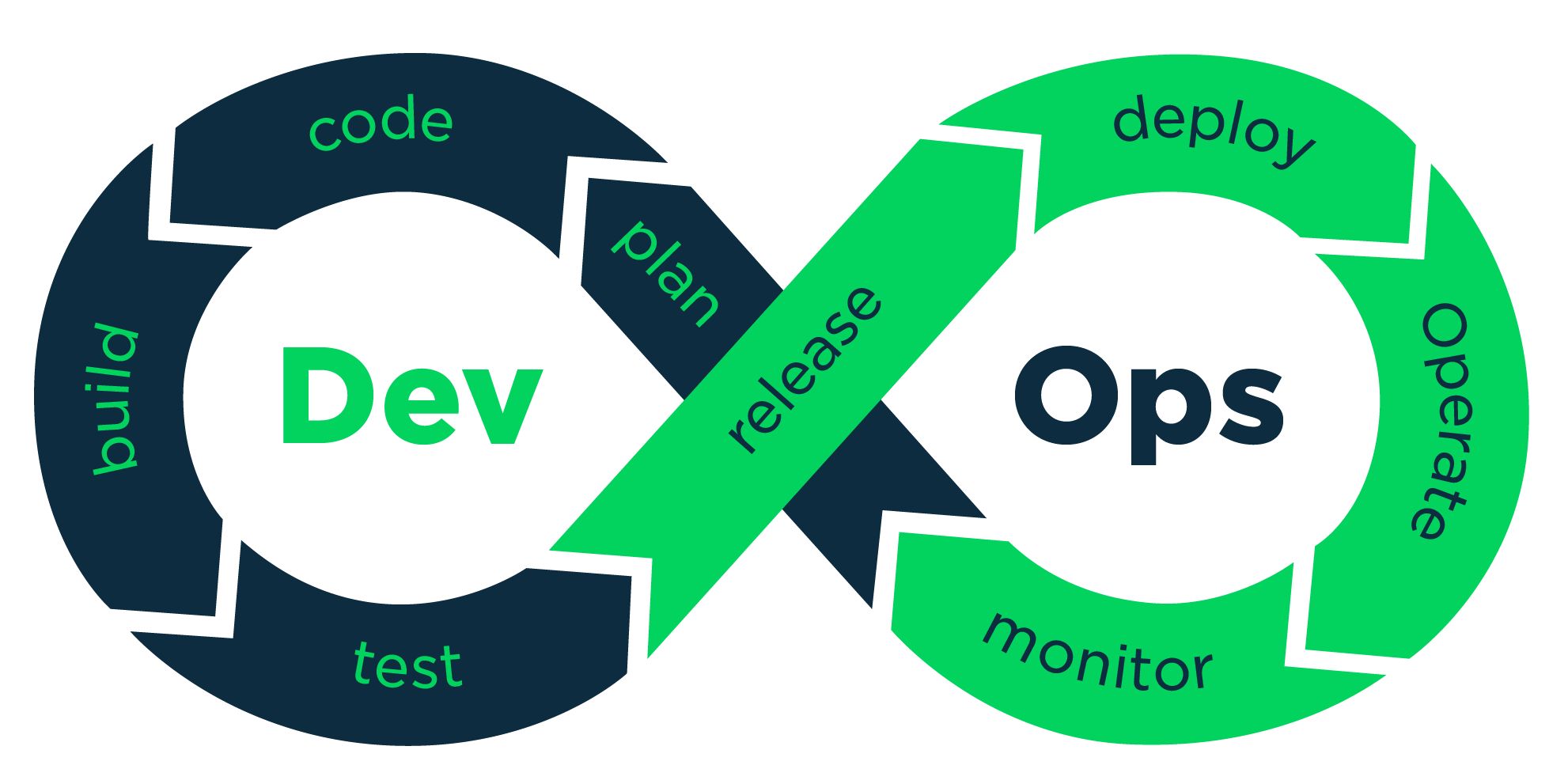
CI/CD
持续集成(Continuous integration,简称CI),
持续集成指的是,频繁地(一天多次)将代码集成到主干。 它的好处主要有两个:
1.快速发现错误。每完成一点更新,就集成到主干,可以快速发现错误,定位错误也比较容易。
2.防止分支大幅偏离主干。如果不是经常集成,主干又在不断更新,会导致以后集成的难度变大,甚至难以集成。
持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量。它的核心措施是,代码集成到主干之前,必须通过自动化测试。只要有一个测试用例失败,就不能集成。
持续交付(Continuous delivery),
持续交付指的是,频繁地将软件的新版本,交付给质量团队或者用户,以供评审。如果评审通过,代码就进入生产阶段。 持续交付可以看作持续集成的下一步。它强调的是,不管怎么更新,软件是随时随地可以交付的。
持续部署(continuous deployment)
持续部署是持续交付的下一步,指的是代码通过评审以后,自动部署到生产环境。
持续部署的目标是,代码在任何时刻都是可部署的,可以进入生产阶段。
根据持续集成的设计,代码从提交到生产,整个过程有以下几步。
(1)提交。流程的第一步,是开发者向代码仓库提交代码。所有后面的步骤都始于本地代码的一次提交
(2)测试(第一轮)。代码仓库对commit操作配置了钩子(hook),只要提交代码或者合并进主干,就会跑自动化测试。 测试有好几种。
- 单元测试:针对函数或模块的测试
- 集成测试:针对整体产品的某个功能的测试,又称功能测试
- 端对端测试:从用户界面直达数据库的全链路测试
(3) 构建。通过第一轮测试,代码就可以合并进主干,就算可以交付了。 交付后,就先进行构建(build),再进入第二轮测试。所谓构建,指的是将源码转换为可以运行的实际代码,比如安装依赖,配置各种资源(样式表、JS脚本、图片)等等。 常用的构建工具如下。
(4) 测试(第二轮)。构建完成,就要进行第二轮测试。如果第一轮已经涵盖了所有测试内容,第二轮可以省略,当然,这时构建步骤也要移到第一轮测试前面。
第二轮是全面测试,单元测试和集成测试都会跑,有条件的话,也要做端对端测试。所有测试以自动化为主,少数无法自动化的测试用例,就要人工跑。
需要强调的是,新版本的每一个更新点都必须测试到。如果测试的覆盖率不高,进入后面的部署阶段后,很可能会出现严重的问题。
(5)部署。通过了第二轮测试,当前代码就是一个可以直接部署的版本(artifact)。将这个版本的所有文件打包( tar filename.tar * )存档,发到生产服务器。
(6)回滚。一旦当前版本发生问题,就要回滚到上一个版本的构建结果。最简单的做法就是修改一下符号链接,指向上一个版本的目录。
软件版本控制
软件开发周期版本控制及称号策略
alpha:内测版,bug多,不稳定,内部版本,不断添加功能
alpha是希腊字母的第一个,表示最早的版本,内部测试版,一般不对外发布,bug多且功能不全,一般只有测试人员使用
Beta1、beta2:公测版,不稳定(比alpha稳定一些),bug相对还多,且不断添加新功能
beta是希腊字母的第二个,公开测试版,比alpha版本晚一些,主要对部分粉丝用户进行测试使用
RC:候选版,经过多个beta版本逐渐稳定,基本不添加新功能,修复完bug即可进入正式发布版
RC是Release Candidate,候选版本。
GA、RELEASE、Stable、Final:正式版,bug很少,推荐生产使用
GA:General Availability
RELEASE:发行版,sping使用
Stabel:稳定版,Nginx使用
Final:最终版本
其他版本称谓:
Free:自由版
Enhance:增强版
Upgrade:升级版
Plus:增加版
Premium:贵价版
Pro/Professional:专业版
Mini/Lite:精简版,只有最基本的功能
Corporation/Enterprise:企业版
直播
视频直播服务目前支持三种直播协议,分别是RTMP、HLS、FLV
- RTMP
实时消息传输协议,由Adobe公司研发,但当前还没有收入国际标准(wikipedia)。协议比较全能,既可以用来推送又可以用来直播,其核心理念是将大块的视频帧和音频帧“剁碎”,然后以小数据包的形式在互联网上进行传输,且支持加密,因此隐私性相对比较理想,但拆包组包的过程比较复杂,所以在海量并发时容易出现一些不可预期的稳定性问题。 - HLS 协议:
基于HTTP协议的流直播(wikipedia)。苹果推出的解决方案,将视频分成 5-10 秒的视频小分片,然后用 m3u8 索引表进行管理。由于客户端下载到的视频都是 5-10 秒的完整数据,故视频的流畅性很好,但也同样引入了很大的延迟(HLS 的一般延迟在 10-30s 左右)。相比于 FLV, HLS 在iPhone 和大部分 Android 手机浏览器上的支持非常给力,所以常用于 QQ 和微信朋友圈的 URL 分享。 - HTTP-FLV 协议由 Adobe 公司主推,格式极其简单,只是在大块的视频帧和音视频头部加入一些标记头信息,由于这种极致的简洁,在延迟表现和大规模并发方面都很成熟。唯一的不足就是在手机浏览器上的支持非常有限,但是用作手机端 APP 直播协议却异常合适。
- WebRTC,名称源自网页即时通信(英语:Web Real-Time Communication)的缩写,是一个支持网页浏览器进行实时语音对话或视频对话的 API。它于 2011 年 6 月 1 日开源并在 Google、Mozilla、Opera 支持下被纳入万维网联盟的 W3C 推荐标准。WebRTC默认使用UDP协议(实际上使用的是RTP/RTCP协议)进行音视频数据的传输,但是也可以通过TCP传输。 目前主要应用于视频会议和连麦中。
https://html.form.guide/email-form/email-form-mailto/
RPC
RPC(Remote Procedure Call),远程过程调用,是一种通过网络从远程计算机上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序直接携带信息数据。
RPC实现了服务消费调用方Client与服务提供实现方Server之间的点对点调用,即包括stub、通信、数据的序列化/反序列化,且client与server一般采用直连的方式
RPC一般是用来实现部署在不同机器上的系统之间的方法调用,使得程序能够像访问本地系统资源一样,通过网络传输去访问远端资源。一般来说,RPC框架的实现原理都是类似的
RPC调用的过程:
客户端调用:负责发起RPC调用,为调用方用户提供使用API
服务端响应:主要是服务端业务逻辑实现
序列化/反序列化:负责对RPC调用通过网络传输的内容进行序列化和反序列化,不同的RPC框架有不同的实现机制,一般分为文本(xml,json)与二进制(java原生的,Hessian、protobuf、Thrift、Avro、Kryo、MessagePack)。需要注意的是,不同的序列化方式在可读性、码流大小、支持的数据类型及性能方面都有较大差距,我们可以根据需要自行选择
Stub:我们看成代理对象,它会屏蔽RPC调用过程中的复杂的网络处理逻辑,使其透明简单,且能够保持与本地调用一样的代码风格
通信传输:即RPC的底层通信传输模块,一般通过Socket在客户端与服务端传递请求和应答消息。
Grpc
Grpc是Google的rpc框架
与分布式服务框架的区别
分布式服务框架除了包含RPC的特性,还包括多台server提供服务的负载均衡、策略及实现,服务的注册、发布与引入,以及服务的高可用策略,服务治理等等。
Monorepo与Multirepo
Monorepo全称是monolithic repo,即单体式仓库, 适用于多个项目之间互有依赖的情况,将所有的相关项目都放在一个仓库里,比如react、Augular、bable、google以及最近放出的vue3等
Multirepo则比较常见,即常见的多仓库管理方式,按项目模块分为多个仓库,开源项目中有webpack、rollup使用这种管理方式
Multirepo的优缺点:
优点:
- 各仓库自由度较高,可以自行选择构建工具,依赖管理、单元测试等配套工具
- 各模块仓库体积不会太大
缺点:
- 仓库分散不好管理,
- 版本更新繁琐,尤其是基本组件库或者公共模块发生变化时,需要对所有的模块进行更新。一个模块改动时,可能需要去相关的板块进行修改再次提交
- CHANGELOG梳理很麻烦,无法很好地关联各个模块的变动联系
Monorepo的优缺点:
优点:
- 一个仓库维护多个模块,不用到处找仓库,提升团队效率
- 方便版本管理和依赖管理。模块之间的引用、调试都非常方便,配合相应工具,可以一个命令搞定,降低基建成本
- 方便统一生成changelog,
缺点:
- 统一构建工具,对工具要求较高
- 仓库体积会变大
实施方案:
从零开始定制一套完善的Monorepo工程化工具是一套很难的事情,可以基于社区进行构建
比较底层的方案比如lerna,封装了monorepo的依赖安装,脚本批量执行,等基本功能,但没有一套完整的构建、测试、部署工具链,因此整体monorepo的功能比较弱,但要用到项目当中,往往需要基于它进行顶层能力的封装,提供全面工程能力的支撑
也有一些集成的monorepo的方案,比如nx、rushstack
lerna
nx
Nx 是一个用来构建 monorepos 的开发工具。自己从 Angular 6.X 版本的时候开始尝试使用 Nx 管理项目代码,那时候的 Nx 还只支持对 Angular 框架的扩展,现在的 Nx 添加了对 React 框架的支持,并且可以集成使用 Cypress, Jest, Prettier, TypeScript 等现在构建工具,支持 NestJs (一款 nodejs 后端框架),完成了对整个全栈生态的覆盖。
创建一个空的 Nx workSpace 项目非常简单,你可以使用以下命令安装
- npx:
npx create-nx-workspace@latest todoapp - npm:
npm init nx-workspace todoapp - yarn:
yarn create nx-workspace todoapp
Nx 支持 Angular, React 和 Nodejs,通过社区扩展也可以支持 Vue, Svelte 或者 Stencil。
前端已经有了那么多的构建工具了,为啥要用 Nx, Nx 的核心优势是啥?Nx 主要是为大型项目构建的,多个项目维护在一个代码库中, 实现项目之间的代码共享,及所谓的 Monorepo,添加了 Cypress, Jest 测试工具,Storybook,集成后端框架,Express,Nest,Next。 所有的项目都可以使用一个代码库管理,并且不会有心智上的负担,不用频繁地切换仓库,也不需要繁琐的配置,还可以在多个项目中共享基础的组件。
首先安装Nx Cli
1 | npm install nx -g |
创建react项目
先添加 React 工具
1 | npm install -D @nrwl/react |
创建项目
1 | nx g @nrwl/react:application reactdemo |
运行时在 start 命令后面加上项目名称就可以
1 | npm run start reactdemo |
有的时候前端项目需要在后端添加一个 Node,用来处理一些特殊的需求,比如 SSR,跨域,API 封装。在 Nx 中添加 Node 项目也很简单, 官方支持 Express 和 Nest。以 Nest 为例,添加 Nest 工具:
1 | npm install -D @nrwl/nest |
创建一个 Nest 项目,并设置代理:
1 | nx generate @nrwl/nest:application nestapp --frontendProject demoapp |
创建nextjs项目
1 | npx create-nx-workspace@latest nx-nextjs-monorepo |
turborepo
内网穿透
测试时用


